Die 3 Arten des maschinellen Lernens
Erklärung der drei Arten von Machine Learning. Zusätzlich gibt es ein kleines Anwendungsbeispiel. Am Ende folgt ein Vergleich der drei Machine Learning Arten.

Lennard Gerdes / 4. April 2023
Dieser Blogpost knüpft an den Wie funktioniert maschinelles Lernen?-Post an. Ich werde dir hier erklären, welche Arten es vom maschinellen Lernen heute gibt und werde dazu dir ein kleines Beispiel präsentieren. Zuerst wird das Überwachte Lernen bzw. Supervised Learning erklärt. Dann folgen das unüberwachte Lernen (Unsupervised Learning) und das verstärkte Lernen (Reinforcement Learning). Hinter allen Arten steht ein Algorithmus, der das Ziel hat, eine bestimmte Aufgabe zu lösen. Die Aufgabe kann zum Beispiel sein, ein Bild zu erkennen oder eine Sprache zu verstehen. Am Ende des Posts folgt ein Vergleich der drei Arten.
Einordnung: Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz. Maschinelles Lernen kann in diese drei Arten wiederum unterteilt werden. Jede Art ist also ein Puzzle-Teil , um das umfangreiche Thema der künstlichen Intelligenz zu verstehen.
Supervised Learning | Überwachtes Lernen
Machine Learning-Algorithmen im Supervised Learning lernen mithilfe von Daten, die mit einem Label versehen sind. Ein Label ist gleichzusetzen mit der Lösung der Aufgabe und das Label wird im vorhinein von einem Menschen bestimmt. Der Mensch muss zuerst alle Daten mit einem Label versehen, damit der Algorithmus aus den Daten lernen kann. Daten die mit einem Label bzw. Lösung versehen sind, werden auch als annotiert bezeichnet. Mit diesen annotierten Daten kann der Mensch den Algorithmus anleiten, wie die Aufgabe zu lösen ist. Im Training nutzt der Supervised Learning-Algorithmus das Label als Vergleichsobjekt. Weicht die Lösung des Labels von der Ausgabe des Algorithmus ab, dann werden bestimmte Parameter durch den Algorithmus eigenständig angepasst. Durch das Training kann ein Supervised Learning Algorithmus Erfahrungen sammeln und Beziehungen bzw. Muster erlernen und erkennen.
Beispiel: Handgeschriebene Zahlen
Ein Beispiel für Supervised Learning Algorithmen sind Bilder mit handgeschriebenen Zahlen. Die Eingabedaten sind Bilder mit handgeschriebenen Zahlen. Das Label in diesem Beispiel ist die sichtbare Zahl auf dem Bild. Der Algorithmus wird mit einer großen Anzahl an handgeschriebenen Zahlen trainiert und erlernt dabei, die verschiedenen Zahlen anhand von Mustern zu erkennen.
Ein Muster ist zum Beispiel die handgeschriebene Zahl „1“. Diese besteht aus einem langen, geraden, vertikalen Strich. Das Muster wird durch die Anpassung der Parameter bis zu einem gewissen Grad erlernt. Durch das repetitive Ansehen und Analysieren von Bildern werden immer mehr Muster erlernt und den verschiedenen Zahlen zugeordnet. Wenn der Supervised Learning Algorithmus ein Muster erkennt, dann gibt dieser seine Entscheidung als prozentuale Wahrscheinlichkeit aus. Das Beispiel soll zeigen, dass der Algorithmus das Bild analysieren und Muster im Bild erkennt. Nach erfolgreichem Training können Entscheidungen getroffen werden, welche Zahl sich auf dem Bild befindet.
Unsupervised Learning | Unüberwachten Lernen
Beim Unsupervised Learning handelt es sich um das unüberwachte Lernen eines Algorithmus. Dem Algorithmus werden Eingabedaten zur Verfügung gestellt, die nicht wie beim Supervised Learning mit einem Label versehen sind. Beim unüberwachten Lernen besteht keine Möglichkeit die Ausgabe des Algorithmus als Mensch anzuleiten bzw. in eine bestimmte Richtung zu forcieren. Desshalb trägt diese Art den Begriff des "unüberwachten Lernens". Das Ziel ist, Muster in den Eingabedaten zu erkennen oder diese zu kategorisieren. Das Erlenen von der Erkennung von Mustern ist vergleichbar mit dem oben erwähnten Beispiel vom Supervised Learning.
Unsupervised Learning wird zur Kategorisierung und zur Reduktion von Dimensionen von Daten verwendet. Daten in einem zweidimensionalen Raum können verständlich visualisiert werden als Daten in einem drei oder vierdimensionalen Raum. Die Kategorisierung ist entweder binär oder die Eingabedaten werden in mehrere Kategorien eingeordnet. Unsupervised Learning wird zudem als Komprimierungsverfahren beziehungsweise Reduktion der Dimensionen eingesetzt. Dabei werden die relevanten Daten von den irrelevanten Daten getrennt und die Dimension des Datensatzes verringert sich. Die Verkleinerung des Datensatzes ist wichtig für die Performance von anderen Algorithmen. Diese können durch die Reduktion schneller die Daten weiterverarbeiten.
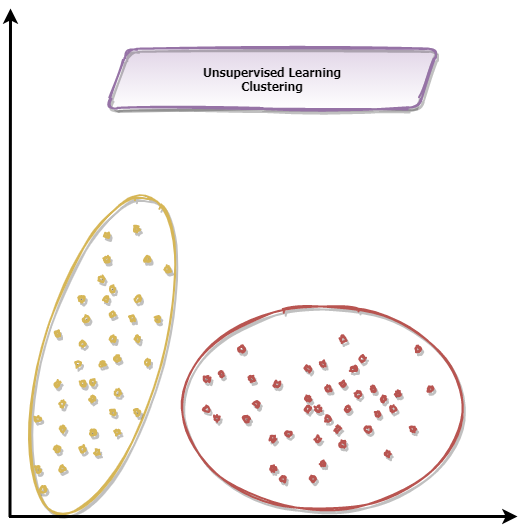
Beispiel: Kreditkartenmissbrauch
Ein Bespiel für unüberwachte Lernen ist das Erkennen von Kreditkartenmissbrauch. In diesem Fall gibt es zwei Kategorien. Es gibt Zahlungen mit Kreditkarte, die "normal" sind und der Besitzer der Kreditkarte hat eine für ihn normale Transaktion getätigt. Das wäre zum Beispiel die Bezahlung des Wocheneinkaufs in einem Supermarkt per Kreditkarte. Ein Missbrauch könnte sein, dass ein Hacker die Kreditkarten illegal erlangt hat und nun eine Reihe von Bestellungen im Internet durchführt. Jede Transaktion stellt einen Missbrauch der Kreditkarte dar und sollte schnell erkannt werden, um den Schaden für die Bank und den Kunden zu minimieren. Der Missbrauch passiert nach einem bestimmten Muster und stellt eine sogenannte Anomalie in den Daten dar. Unsupervised Learning kann für das Erkennen von Kreditkartenmissbrauch trainiert und eingesetzt werden. Allgemein kann diese Art von Anomalie-Mustererkennung in viele Bereichen eingesetzt werden. Wie Airbus diese Art für die Internationale Space Station (ISS) einsetzt und damit gefährliche Situationen abwendet, kannst du hier lesen.
Reinforcement Learning | Verstärktes Lernen
Einem Computer das Lernen beizubringen steht in direkter Verbindung mit dem menschlichen Lernen. Kinder lernen durch die Interaktion mit ihrer Umwelt. Die Interaktion führt zu neuen Informationen und Erkenntnissen über die Umgebung. Die Verknüpfung der Ursache (Handlung) mit der jeweiligen Wirkung (Konsequenz) ist das Fundament des Lernens. Der englische Begriff „Reinforcement Learning“ wird im Deutschen als „verstärktes Lernen“ bezeichnet. Die Grundlage für das Reinforcement Learning wurde aus dem Markow Entscheidungsprozess übernommen. Der Prozess beschreibt mathematisch, wie ein System in einer Umwelt eine Reihenfolge von Entscheidungen treffen kann. Dazu braucht es fünf verschiedene Bestandteile: Zeitepochen | Einteilung von Zeitabschnitten (z.b. Sekunden, Minuten usw.) Reihe von möglichen Zuständen eines Systems Reihe von ausführbaren Aktionen des Algorithmus im System Liste von Zustand und Aktionspaaren, die mit Kosten oder einer Belohnung verknüpft sind Liste von Zustand und Aktionspaaren, die mit Übergangswahrscheinlichkeiten verbunden sind Diese fünf Bestandteile bilden das Fundament vom Reinforcement Learning. Der Kern von Reinforcement Learning Algorithmen ist der Agent. Dieser befindet sich in einer Umwelt, in welcher ein Agent lernen kann, ein Ziel effizient zu erreichen. Um das Ziel zu erreichen, braucht es eine Sequenz von Aktionen. Je nach Ausführung einer Aktion, begibt sich der Agent in einen neuen Zustand. Der Zustand beschreibt dessen aktuelle Lage. Analog zu einem menschlichen Kind interagiert der Agent mit seiner Umgebung durch Aktionen. Dabei erfährt der Agent eine Konsequenz durch eine angemessene, positive oder negative Belohnung. Die Verknüpfung zwischen Aktion und Belohnung wird vom Agenten gelernt. Anders als beim Supervised Learning bekommt der Agent kein Training mit Daten, die mit dem richtigen Label versehen sind. Der Agent probiert im Training verschiedene Aktionen aus, um herausfinden, für welche Lösung dieser die maximale Belohnung bekommt. Am Anfang des Trainings besitzt der Agent keine Informationen über die Zustände der Umwelt und die entsprechenden Belohnungen. Die Informationen werden durch Erkundung der Umwelt gelernt. Im Training lernt der Agent, welche Reihenfolge von Aktionen seine gesamte Belohnung maximiert. Die Sequenz der Aktionen soll den Agenten effizient an sein Ziel bringen.
Beispiel: Entkommen aus einem Labyrinth
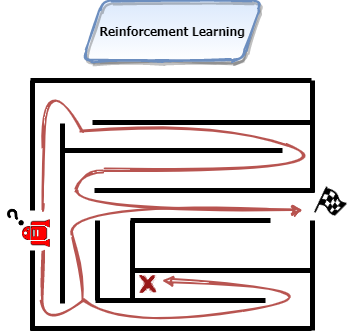
Ein einfaches Beispiel für ein Reinforcement Algorithmus ist das Lösen bzw. Entkommen aus einem Labyrinths. Das Labyrinth ist in diesem Fall die Umwelt, in der sich der Agent befindet. Auf einem festgelegten Startpunkt startet der Agent und kann das Labyrinth durch die verschiedenen Aktionen erforschen. Das Ziel ist, einen Ausgang aus dem Labyrinth zu finden. Der Ausgangspunkt ist mit der größtmöglichen Belohnung verknüpft. Wo dieser Ausgangspunkt liegt, weiß der Agent zum Startzeitpunkt des Trainings nicht. Die Aktionen, die ausgeführt werden, sind die einzelnen Schritte in eine beliebige Himmelsrichtung. Wie jeder Mensch, würde der Agent zuerst wahllos durch das Labyrinth irren ohne jeglichen Plan. Durch das zufällige Erreichen des Ausgangspunktes wird der Agent die größtmögliche Belohnung erhalten. Die Belohnung, die dem Ausgangspunkt zugeordnet ist, ist im Vergleich größer als die der anderen Zustände. Nachdem das Ende des Labyrinths erreicht wurde, wird der Agent wieder auf den Startpunkt zurückgesetzt. Er hat die ersten Zusammenhänge verstanden und gelernt, trotzdem braucht es mehrere Durchläufe, um die komplette Umwelt zu erkunden und um einen idealen Weg zu finden. Durch das erlernte Wissen wird der Agent nicht mehr wahllos durch das Labyrinth irren, sondern die gelernten Aktionen immer wieder in der gleichen Reihenfolge wiederholen. Der Agent kann mithilfe von Hyper-Parametern eingestellt werden und ein beinhalteter Parameter legt fest, wie gierig der Agent nach Belohnung ist. Je gieriger der Agent, desto weniger wird die Umwelt erkundet. Die Folge ist, dass die Sequenz der Aktionen eventuell nicht dem effizientesten Weg entspricht. Sein niedriges Bestreben, die Umwelt zu erkunden, führt dazu, dass eventuell der effizienteste Weg nicht erkundet wird und stattdessen immer wieder eine Sequenz von bestimmten Aktionen genutzt wird. Wenn der Agent weniger gierig ist, dann wird der Agent stärker die Umwelt erkunden und zusätzliche Schritte unternehmen. Zusätzliche Schritte sind nicht förderlich, um effizient ein Ziel zu erreichen. Der Vorteil der Erkundung ist, dass mehr Informationen über die Umwelt aufgenommen werden, um bessere Entscheidungen in der Zukunft zu treffen. Die Umwelt wird für neue Informationen erkundet und genutzt, um einen Weg zu finden, der den Agenten effizient aus dem Labyrinth bringt. Es gibt einen Zielkonflikt zwischen Erkundung und Ausnutzung. Wie sehr sich der Agent auf das Maximieren der Belohnung oder auf das Erkunden der Umwelt fokussiert, lässt sich durch den Hyper-Parameter der Gier steuern.
Vergleich der 3 Arten des maschinellen Lernens
Supervised Learning braucht annotierte Daten. Mit diesen annotierten Daten kann ein Mensch den Supervised Learning-Algorithmus "lenken" eine bestimmte Aufgabe zu lösen. Diese Art ist sehr stark auf die Lösung der Aufgabe fokussiert und die Menge an Daten die benötigten werden, sind enorm. Unsupervised Learning braucht keine annotierten Daten erhalten und ist quasi "auf sich alleine gestellt" mit den Daten. Unsupervised Learning soll lernen, etwas über Daten herauszufinden, diese sortieren oder kategorisieren. Sofern eine Kategorisierung erlernt worden ist, kann der Algorithmus auf neue (nicht im Training enthalten) Daten angesetzt werden, um diese ebenfalls zu kategorisieren oder deren Dimensionalität zu reduzieren. Hier gilt auch wieder. Je mehr Daten dem Algorithmus in der Trainingsphase bereitgestellt werden, desto präziser kann der Algorithmus neue Daten kategorisieren. Reinforcement Learning ist deutlich komplexer als die beiden vorherigen Arten. Die Aufgabe besteht darin, dass sich der Agent des Algorithmus in einer unbekannten Umwelt zurechtfinden und erkunden muss, ohne die Hilfe eines Menschen. Zusätzlich hat der Agent des Reinforcement Learning noch eine zweite Aufgabe. Es reicht nicht nur aus die Umwelt zu erkunden. Er muss zudem aus der Erkundung-Phase die richtigen Schlüsse ziehen, um einen effizienten Weg zum Ziel zu finden. Der Algorithmus lernt durch Trial-and-Error. Im Reinforcement Learning braucht es keine großen Datenmenge. Es wird lediglich ein Agent und eine Umwelt gebraucht. Die Umwelt teilt dem Agent durch Belohnung oder Bestrafungen, die Konsequenz seiner letzten Aktion, mit. Aus diesem Zusammenspiel kann der Algorithmus lernen. Reinforcement Learning wirkt sehr menschlich und es ist die Art, die am meisten Potenzial verspricht und schon eher an das generelle Verständnis (laufende Roboter, selbst fahrende Autos, Entscheidung-Helfer) von Künstliche Intelligenz rankommt.
Fazit
Alle drei Arten des Maschinellen Lernen haben eine Aufgabe und ein Ziel. Alle drei Arten durchlaufen eine Trainingsphase in der das Lösen einer bestimmten Aufgabe gelernt/erlernt wird. In der Trainingsphase wird diese Aufgabe hunderte male gelöst und daraus entsteht ein Wissenstand. Nach der Trainingsphase wird erwartet, dass der Algorithmus eine vergleichbare Aufgabe lösen kann. Die benötigten Voraussetzungen jeder Art des maschinellen Lernens unterscheiden sich hingegen deutlich. Welche Art eingesetzt werden kann, hängt von der jeweiligen Aufgabe und den vorliegenden Daten ab.